Remember The Matrix? Yes, that Matrix, the one with leather trenchcoats, bullet-time and simulated steaks.
It was something special at the time - and it also had one of the coolest representations of a computer virus: the infamous Agent Smith, the self-replicating virus embodying the consciousness of a single agent, duplicating itself over and over again, chasing our heroes across the simulation. His superpower lied in his ability to create new instances of himself at any moment, creating and dispatching them to do whatever task needed to be done.
And in this new era of Generative AI, there is one pattern that has consistently proved itself as a core primitive of the LLM world - the Agent. If you haven’t heard of the Agent pattern yet, you can think of it just like you’d think of Agent Smith - it’s an embodied instance of your LLM - specialising in whatever task you need it to perform, be it writing code, translating inputs, invoking functions or writing haikus about Rust. The Agent pattern allows us to perform more accurate LLM calls, parallelise work and even more important - orchestrate agents by letting one "main" agent dispatch work to others.
So let’s take a dive and look at how we can harness the power of LLMs and build agents of our own using Rust.
Why build them in Rust?
You mean except the speed, efficiency, portability?
Because when developing with agents - especially letting them run functions and code on our machines - we want to make sure we're running it as safe as possible. The memory safety provided by Rust can work as a nice isolation to common attacks, leaving our services safe from any potential exploits via code injection (And of course, if the AI breaks out of the box, having it sandboxed inside a Rust program might just prevent the AI-pocalypse from happening).
But besides safety, the error handling and pattern matching abilities Rust provides can ensure that our code works correctly, which when working with AI agents is quite important. As LLMs can often hallucinate and make mistakes, catching them on time and handling them in a proper manner is extremely important for any production usecase - you don't want your users to get wrong data, or even worse - someone else's data. For such things, Rust's powerful error handling really comes handy, allowing us to build safety latches into our product easily.
All of this, when combined with the powerful trait & macro abilities, allows us to create and combine our abstractions safely and enabling us to scale our agents into complex networks with ease. When building real-life usecases that depend on multiple agents working together in sync, you'll find that the number of agents can grow quite fast, especially when adding different evaulation or format translation agents, making it of paramount importance to choose a language that enables you to easily build strong abstractions.
Agents 101
While Agents might sound like some super complex thing, especially with multiple frameworks and libraries offering similar abstractions, building them is quite simple - they usually consist of a few things:
- The System message - system message is in a way the “core” of your agent, defining its purpose and behaviour. It primes your LLM with instructions on how to behave and answer to your messages.
- The model definition - usually agents also contain reference to the model used, allowing us to switch between more powerful models for accuracy or smaller and faster models for efficiency.
- The supported functions - especially useful if you want to allow your agents to invoke functions from your code, using tools like OpenAPI’s function calling to invoke different functions depending on the data provided.
So let's create some agents of our own. Start up your favorite editor, create a Rust project and let’s go and define a simple Agent struct that will take care of these things for us:
pub(crate) struct Agent {
pub(crate) system: String,
pub(crate) model: String,
}
Now, we also need a way to actually use our agents, so let’s add some extras to the struct.
First off, we need to be able to prompt the agent and give it a task to perform. For this, we’ll create a prompt method that simply takes in a string and returns a string. So let's create our prompt function:
impl Agent {
async fn prompt(&mut self, input: String) -> Result<String, Error>
}
Usually, to make these agents even more useful, we'd also want them to be able to remember their conversation history, allowing us to build some kind of context through the conversation. So let’s also add a history field that will contain the list of messages. Messages can be created either by the agent itself or by the user, so we’ll create an enum to differentiate between them - we’ll also add an enum for the System message, since that is the first message all agents will receive.
To make them future-proof, we’ll also expose the history to the outside world, so we can imbue our agents with predetermined messages or fork new agents from existing ones.
While for our example usecase this won't be relevant, in larger and more complex usecases you will probably encounter the need to use message history to remember the context of the previous executions. So let's add those bits of code too:
pub(crate) enum Role {
AGENT,
USER,
SYSTEM
}
pub(crate) struct Message {
pub(crate) content: String,
pub(crate) role: Role
}
pub(crate) struct Agent {
pub(crate) system: String,
pub(crate) model: String,
pub(crate) history: Vec<Message>
}
And that is it - the basic building blocks for our agents are in place. Now, how to actually use them?
Defining the agent's purpose
To actually use our agents, we need to give them a purpose, otherwise they will only be acting like generic LLM models - okay, but not great. By giving them a proper purpose through the system message, we prime them to act a certain way, giving us increased accuracy on tasks.
So for this article, we’ll make two simple agents that can be used both together or independently:
- First, we’ll create one Agent that will receive a YouTube video and summarise the main talking points for us.
- Then, we’ll create another agent that will take that summary and actually make it usable, by translating it to JSON we’ll consume inside our code.
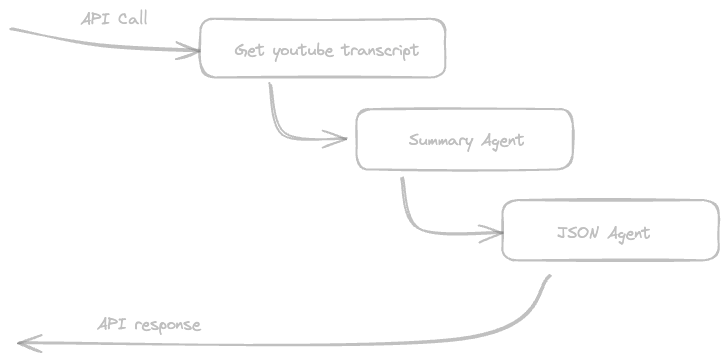
Now, you might be wondering why use two separate agents when this could be rolled into one?
Well, while LLM’s are quite capable, they’re also quite fickle machines - their outputs are quite non-deterministic, so every time we provide the same input, we might get a different output. By trying to squeeze both tasks into a single agent, we increase the chance of having erroneous, inaccurate and unwanted results. For example, if we can achieve 80% accuracy on one task, then accuracy for two tasks could fall to 64% (80% x 80%) - but since these are LLM’s, the accuracy can fall even more due to the first task priming the LLM into a specific local minima, i.e. it being more focused on the first task. That is why when developing with LLM agents, the best philosophy to follow is the UNIX philosophy:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
Incredibly, this nearly 50-year old philosophy serves us well even today and fits perfectly with the LLM world. So let’s create our two agents by following it. First, we’ll create our Summarising agent.
To do that, we need to implement our Agent trait. For this, we’ll be using the most popular of the LLM providers - OpenAI - and we’ll access it using the async-openai crate, giving us some simple abstractions over it. So pop open your terminal and add the dependency:
cargo add async-openai
To be able to use the async-openai crate, we also need an API key from OpenAI - you can find it here. To use it, just add it to your environment variables or open your terminal and hit:
export OPENAI_API_KEY='your-key-here'
Now, let’s create an implementation of the prompt method - it’s quite simple, we’ll just add the OpenAI Client to our agent and map the prompt method to the async_openai’s prompt:
pub(crate) struct Agent {
pub(crate) system: String,
pub(crate) model: String,
pub(crate) history: Vec<Message>,
pub(crate) client: Client<OpenAIConfig>
}
impl Agent {
pub(crate) async fn prompt(&mut self, input: String) -> Result<String, OpenAIError> {
//If you are remembering the message history, you can restore it from here.
self.client.chat().create(
CreateChatCompletionRequestArgs::default()
.model(self.model.clone())
.messages(vec![
//First we add the system message to define what the Agent does
ChatCompletionRequestMessage::System(
ChatCompletionRequestSystemMessageArgs::default()
.content(&self.system)
.build()
.unwrap(),
),
//Then we add our prompt
ChatCompletionRequestMessage::User(
ChatCompletionRequestUserMessageArgs::default()
.content(input)
.build()
.unwrap(),
),
])
.build()
.unwrap(),
).await.map(|res| {
//We extract the first one
res.choices[0].message.content.clone().unwrap()
})
//Now here, you can save the prompt and agent response to the history if needed
}
}
With that out of the way, we can create the actual first instance of our agent by defining its system prompt and passing it in. So let’s write down some instructions that will go in the system prompt.
static SUMMARY_PROMPT : &str = r#"You are an agent dedicated to summarising video transcripts.
You will receive a transcript and answer with main talking points of the video first,
followed by a complete summary of the transcript. Answer only in this format:
Talking points:
1. ..
2. ..
N. ..
Summary:
Summary of the transcript
"#
But first - we need the transcript. To fetch the transcript itself, we’ll be using the youtube-captions crate. While getting the transcript can be quite straightforward using the API, we’ll do it the lazy way and let the crate do the job for us. To do the HTTP request, we'll also need the famous reqwest crate, together with serde and serde-json to deserialize the JSON into a struct. So head on to your Cargo.toml or terminal and add the crates:
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
youtube-captions = "0.1.0"
reqwest = "0.11"
To keep it nice and tidy, let's create a get_transcript(video: &str) -> String method. First, we'll use the youtube-captions scraper to get the captions:
async fn get_transcript(video: &str) -> String {
let digest = DigestScraper::new(reqwest::Client::new());
// Fetch the video
let scraped = digest.fetch(video, "en").await.unwrap();
// Find our preferred language - in this case, english
let language = LanguageTag::parse("en").unwrap();
let captions = scraped.captions.into_iter()
.find(|caption| language.matches(&caption.lang_tag))
.unwrap();
let transcript_json = captions.fetch(Format::JSON3).await.unwrap();
}
Since youtube doesn't return us the pure caption text but JSON, we'll need to deserialize the captions. To do that we need some structs matching the format - one for the whole transcript, one for the video events and one for the captioned segment itself, which will contain the captioned UTF-8. So let's make some and mark them with serde's Deserialize macro:
#[derive(Deserialize)]
struct Transcript {
events: Vec<Event>,
}
#[derive(Deserialize)]
struct Event {
segs: Option<Vec<Segment>>,
}
#[derive(Deserialize)]
struct Segment {
utf8: String,
}
With this, we can deserialize the received object and extract all the captions, joining them together into one giant string.
So open up the get_transcript method and let's flatten them all together:
async fn get_transcript(video: &str) -> String {
// ...
// after fetching the transcript
let root: Transcript = serde_json::from_str(transcript_json.as_str()).unwrap();
// Collect all utf8 fields from all events and all segments
let transcript: String = root.events.iter()
.filter_map(|event| event.segs.as_ref())
.flatten()
.map(|segment| segment.utf8.clone()) // Extract the utf8 field of each segment
.collect::<Vec<String>>()
.join(" ");
return transcript
}
Now, we're ready to build our agents and put them to work!
Let’s create a summarize_video function that will wrap it all up - take in the video ID and return us a nice summary of the text. First, we’ll use the get_transcript method to get the video’s transcript, then we'll pass it on to our agent to summarise it for us.
async fn summarize_video(video: &str) -> String {
let client = Client::with_config(
OpenAIConfig::default(),
);
//First, we fetch the transcript for the video
let transcript = get_transcript(video).await;
// Then we create our summary agent and have it summarize the video for us
let mut summarize_agent = Agent {
system: SUMMARY_PROMPT.to_string(),
model: "gpt-4".to_string(),
history: vec![],
client: client.clone(),
};
let summary = summarize_agent.prompt(transcript).await.unwrap();
}
Next, we’ll create another agent - one that will take the summary and translate it into the JSON format of our choice. So let’s write a new system message for our Agent. To make sure it follows a specific format, it’s best to include the format example and some basic rules:
static SUMMARY_TO_JSON_PROMPT = r#"You are an agent dedicated to translating text to JSON. You will receive the text and return it in JSON format.
The format is as follows:
{
“summary”: “Whole video summary goes here”,
“talking_points”: [
{
“title” : “Title of the point”,
“description: “Talking point summary”
},
...
]
}
Rules:
- Follow the specified JSON format closely
- Wrap the JSON in a code block
- Skip prose, return only the JSON
"#
And now we can wrap it all together:
//In summarize_video
...
let mut summary_to_json_agent = Agent {
system: SUMMARY_TO_JSON_PROMPT.to_string(),
client: client.clone(),
model: "gpt-4".to_string(),
history: vec![],
};
let json = summary_to_json_agent.prompt(summary).await.unwrap();
return json;
But hold on, we're not done yet - here’s the thing - since LLM’s can be fickle, we cannot be certain that the output will contain only the JSON, so we’ll add an extra utility method that will extract the codeblock from the response.
fn extract_codeblock(text: &str) -> String {
if !text.contains("```") {
return text.to_string();
}
let mut in_codeblock = false;
let mut extracted_lines = vec![];
for line in text.lines() {
if line.trim().starts_with("```") {
in_codeblock = !in_codeblock;
continue;
}
if in_codeblock {
extracted_lines.push(line);
}
}
extracted_lines.join("\n")
}
We can use this on the received response and extract the codeblock if it exists - otherwise, it will return the whole text.
//...
let json = summary_to_json_agent.prompt(summary).await.unwrap();
let result = extract_codeblock(&json);
return result
Bringing the agents live
Finally, we’re ready to use our agents. But uhhh wait, how do we actually use them? If we plan to use them from a frontend, we’ll need to create an API around that. Luckily, we can use Shuttle and Axum together to get an API up and running quickly.
First, you need to install Shuttle - just hit cargo binstall cargo-shuttle and it should install in no time.
So let’s open up that Cargo.toml and add the required dependencies - we'll add axum and shuttle-axum to build the server, tokio for async work and the shuttle-runtime to run in Shuttle's cloud.
axum = "0.7.3"
shuttle-axum = "0.44.0"
shuttle-runtime = "0.44.0"
tokio = "1.28.2"
Now, pop open the main.rs and let’s create a simple server we can deploy to Shuttle:
async fn main() -> shuttle_axum::ShuttleAxum {
let router = Router::new();
Ok(router.into())
}
Yes, that's really everything you need to start & deploy a server - quite amazing, isn't it?
Now, let's add to the router an endpoint that will wrap it all together. We'll keep it simple, passing in the video ID through the path itself - so you can replace the youtube.com/watch?v=VIDEO_ID url with just ourservice.com/VIDEO_ID, keeping the API simple and concise. With Axum, adding endpoints is super easy - we just define the endpoint path and write the function. For this one, we'll use a GET /:video_idand pass it in the video ID in the path itself.
So let's add a function that will get this path and invoke our summarize_video:
async fn summarize_endpoint(Path(video): Path<String>) -> String {
let summary = summarize_video(video.as_str()).await;
return summary;
}
And add it to our Axum configuration:
#[shuttle_runtime::main]
async fn main() -> shuttle_axum::ShuttleAxum {
let router = Router::new().route("/:video", get(summarize_endpoint));
Ok(router.into())
}
With this we can finally deploy - just hit cargo shuttle project start && cargo shuttle deploy --ad, grab a coffee and you'll find your agents spinning in Shuttle's cloud, ready to be used. So let's test it out - we'll use the Shuttle AI announcement video as an example. For now, we'll keep it simple and just use curl - later, you can also build a frontend for it, using something like Next.js or one of Shuttle's starter templates.
So let's bring up your terminal and curl it:
curl "yourprojectname.shuttleapp.rs/6sHo-2ddw3U"
If you've done everything right, you should receive back the summary and key points as a JSON - if you see something about Chateau instead of Shuttle, don't worry, nothing's broken - except Youtube's auto-caption service. Maybe they should rewrite it in Rust? :)
But now that you're done, give yourself a high-five - you deserved it - then go build that frontend. And feel free to share it with us on Discord - we're eager to see what you'll build!