When building Shuttle, we’ve always focused on how we can help developers. With our infrastructure-from-code offering, we hoped to solve the challenge of provisioning and managing a complex infrastructure. We wanted to give developers the ability to build, test, and deploy their apps without having to worry about managing servers or drowning in console commands.
But, we never thought about how we could help machines too.
With the recent advent of LLM’s and their - sometimes unbelievable - ability to “understand” human language and turn it into working code, it felt like we were on the verge of something revolutionary. It felt like the whole area of software development is about to shift.
Yet, while they helped humans write code and develop faster than ever, LLM’s still haven’t broken the barrier of doing end-to-end work - writing down specifications, generating a whole app, provisioning services, deploying it. But while the code-generation is possible through a combination of model-chaining and output parsing, the latter is where it becomes problematic - you need to be able to provision resources, which means letting the model connect to your AWS account, your shell or manually provisioning services - and none of it sounds like too smart of an idea. We’ve all seen Terminator, we all know how giving an AI access to the shell turns out.
Luckily, our ability to connect and provision infrastructure straight from code has put us in the perfect position to be the glue LLM’s need to complete the end-to-end part of the equation. So we decided to try and see how we can help out the developers be more productive, and ended up taking a peek into the future of programming.
And we’re finally ready to give you a peek into it too - presenting
Shuttle AI
Repetitive work is one of the most annoying parts of every project. We all like doing the fun, challenging stuff but we sure don’t enjoy reinventing the wheel for a hundredth time or writing the same boilerplate over and over again. When you have an idea, you don’t want to spend time wrangling infrastructure or debugging authentication implementations.
But, did you ever wonder what if we could skip the boilerplate? What if we could have an AI write it for us, going from an idea to a fully-fledged MVP in a few minutes? How much time could it save? How many new products could it help launch? Wouldn’t it be cool if we could just like Tony Stark, wave our hands around and have Jarvis turn our ideas into reality?
Well, wonder no more.
In collaboration with @Ian Rumac, we’ve developed a new GPT-4 powered tool to help you develop, run and deploy a whole Rust-based web app to the cloud with a single command. It’s the fastest way to go from an idea to production, even faster than deploying a “hello world”.
How?
You just need an idea - want to build a revolutionary new blogging service?
Just write shuttle-ai build "Make me a simple blogging service" and while you go and grab a cup of coffee, Shuttle’s AI agents will breakdown the project, generate the needed code, ensure it compiles, provision the infrustructure and deploy it to Shuttle’s Cloud, returning you a live, fully-working backend app and the generated code.
Missing a feature?
Just write shuttle-ai add-feature “Add commenting support”, sit back and watch as our AI agents analyse your code, update it and deploy the new changes to it.
But enough talking, here’s that sneak peek we promised:
Now, while this is just a small preview of our new tool’s capabilities, we will soon be opening it up to more testers, and we’re hyped to see what everyone will be able to build with it.
And no worries - we’ve all seen generated code before and know how messy it can get. That’s why the generated code is standard Rust code and is completely human-readable and if you want to maintain it yourself, you will find it easy to understand and navigate. All of the infrastructure is provisioned via Shuttle, and your backend can also be ran locally using cargo shuttle run.
Choosing Rust
While Rust is one of the most loved languages and praised for it’s performance and reliability, it is also notorious for it’s strictness and learning curve. That strictness makes it perfectly positioned as a language for code-generation - if it compiles, you have the confidence in the codebase and it’s inner workings - while it does not provide the confidence of good test-coverage, it narrows the possible bug area. Using a dynamic language like Javascript would be able to make our job easier, but the confidence in the generated code would be quite low due to it’s dynamic properties.
On the other hand, while Rust has a large learning curve, more and more developers are trying it and joining the Rust community. So generating a simple service they can play with and experiment on seems like a perfect opportunity to help them get over the curve easily and quickly become productive in Rust.
Behind the scenes
Behind the scenes lies a process with multiple GPT Agents, working in tandem to generate code, make it deployable and fix any errors along the way. Let’s take a look behind the curtain and see how the process works:
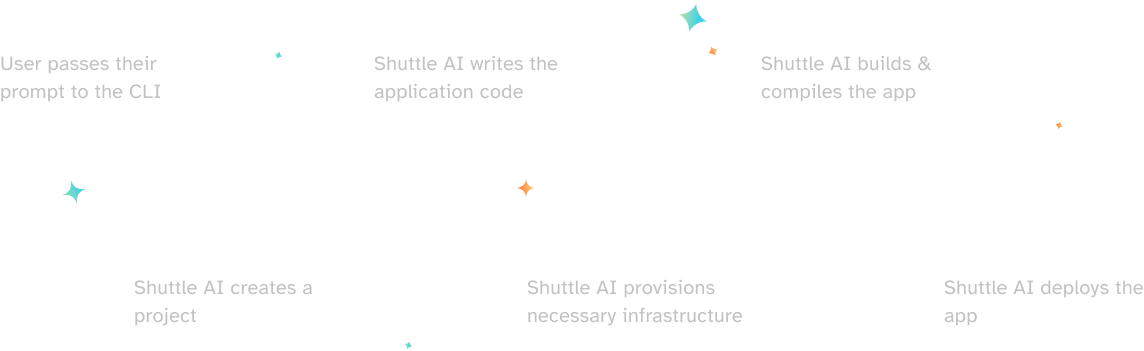
First, we start with an agent that expands upon the users prompt, generating us a JSON-based specification of the project. This allows us not just interact with the results, but to expand the context and strictly define the set of work the agents will perform. This includes a longer description of the app, a set of endpoints it will generate and a set of models necessary for your app to run, as well as any features you might need, i.e. a database.
After this, we turn over to the generation agents themselves, starting with the necessary models - be it SQL schema, just entities or both - then continue to generate endpoints using those exact models, culminating with the generation of the main file and the cargo file itself after all of the dependencies are known. This part of the process is done in order to ensure proper knowledge exists in the context before generation occurs.
Before we continue, we run it through implementation agents, which check if there is any code we haven’t implemented yet and we generate it before the code leaves for deployment.
To make it deployable, we developed “Shuttlify” agents, that update the code with necessary dependencies and annotations to provision Shuttle infrastructure. While this tool currently resides inside Shuttle AI, we find it is quite useful for our community too, and we will soon be extracting it to a standalone tool, so you can migrate your existing projects to Shuttle in no time.
While LLM’s are amazing and generate all this code for us - they still make mistakes - that’s why before deployment, we check the code for compilation issues and if any are found, we push it to our compiler-agent feedback loop. This loop provides the errors to an agent which reasons about it, as in “what caused this error? what does that imply?” and creates a plan - “what are the steps to fixing it? “ which we can parse and implement step by step, providing the agent that does the actual fixes with more context, ensuring better results.
But, even with the best of reasoning, these agents can sometimes get stuck in a minima, trying to achieve impossible things or just hallucinating plainly wrong code. To get out of this, we ramp-up the temperature of the calls depending on the compilation results. While this is not a perfect solution, it often can help the machine break out of it’s loop and start again with a clean slate and a chance to take a different path.
Now, with all these agents, you sure must be wondering - what about the prompt limit?
Well, while currently this is quite a limitation and generation of large-scale projects is still not feasible (except with access to Claude or GPT4-32k), we’re managing to stay under it it by performing agent-splitting.
Agent-splitting allows us to clone off an agent at a certain point in conversation, which can be used to either split the independent parts of the task into a new agent, parallelise work or imbue a new agent with the context of a previous one by copying it’s history.
Limitations
While the technology is pretty amazing and we are enjoying watching it build a whole codebase out of a simple prompt, we are well aware of some of it’s current limitations and challenges. We are working actively to resolve some of them, but also are looking forward to the latest LLM technology improvements allowing us to implement better solutions and larger projects.
Some of the encountered limitations are:
-
Context size, i.e. token limits in models. While it is possible to stay under them using different techniques, they are still an issue when a sufficiently large project is in question. Since code heavily relies on other code, providing less code can limit the context in which an LLM operates and increase the changes of the code not applying to the codebase. While we are currently in alpha and don't expect anyone to generate large-scale production projects, we are already using some techniques and actively exploring alternative approaches and updates to our process to avoid this limitation.
-
Business logic - while often times the logic will be correct, LLM’s still make mistakes, especially without enough information. This can be avoided by giving a more detailed prompt, but also by writing tests. While we have currently not implemented a test-writing component, it is in our short-term roadmap, along with other new tools that will enable you to have more confidence in the generation results and in your code.
-
Hallucinations and local minima - one of the things we have to admit to ourselves when using LLM’s is that they often hallucinate. And if you use them in a conversational manner as a part of an automated process, a single hallucination can often lead the LLM into a path that ends up looping, i.e. it starts applying hallucinations to fix it’s hallucination-caused errors. While this problem is natural due to the way of the technologies inner workings, it is also avoidable by steering the LLM with a set of right rules and examples, or raising the temperature to get a different response path. We're applying multiple of these techniques, which combined with Shuttle's large repository of samples, help reduce hallucinations to a minimum.
-
Costs and privacy of LLM’s - While we are currently using GPT-4, we are well aware of it’s costs and privacy issues. Yet, while this is still in an early phase, we do not expect anyone to use it to generate proprietary code or hundreds of codebases. To get around these issues, we are looking into using self-hosted models, or even fine-tuning existing ones. In the future releases, we will also look into the ability of allowing users to provide tokens or even use pick-an-LLM approach.
The implications of LLM's & code generation
While building a tool like this, it’s not uncommon to wonder “what does this imply about our future as developers”. While we often joke it’s going to put us out of work, the realistic perspective is that it won’t - it will just make us insanely more productive and let us enjoy our jobs even more. As developers, we find we enjoy solving challenges and improving things, not writing repetitive infrastructure and boilerplate to support our code. And LLM’s are able to remove the repetitiveness out of the way on a larger scale than any other development tool before them.
On the other hand, we have had code generation for years, just not in this amount of detail. Tools like wizards, scaffolders and bootstraping toolkits (such as Shuttle’s recent NextJS & Rust SaaS boilerplate) have existed for a long time and have impacted the productivity of the developers in a huge way, creating more amazing products and companies along the way than it was possible ever before.
We are happily looking forward to the future of this technology and all the potential innovations and products it will help create - and especially the ones you create with Shuttle AI!
When can I use it?
While Shuttle AI is currently in a private alpha, you can join the waitlist to be among the first to get access to it or join our Discord to find out more.
If you have any questions about the tool, feel free to reach out to us on Twitter or Discord. We’d love to hear what you think and learn how we can make this even more useful for you!